
Mozenda
Mozenda is a dynamic platform that provides web scraping services for hundreds of web pages. It can easily scrape files, images, PDF, and text from web pages with the most advanced click and point feature. You can smoothly export all your data files for publishing in an attractive and improved way. It offers a valuable API that allows you to export data files directly to CSV, XML, XLSX, JSON, and TSV. This innovative platform prepares and organizes all your data to make better and big decisions in a perfect way.
Mozenda performs all the duties of data projects such as building, delivering, and maintaining. It seamlessly fulfills all your requirements related to data. You can utilize all the extracted data for growth, operations, research, sales, marketing, and multiple strategies. It offers you to chat directly with the professional support teams for any query or problem. Furthermore, it is an all-in-one platform that extracts data at the fastest speed and automatically stores all your data.

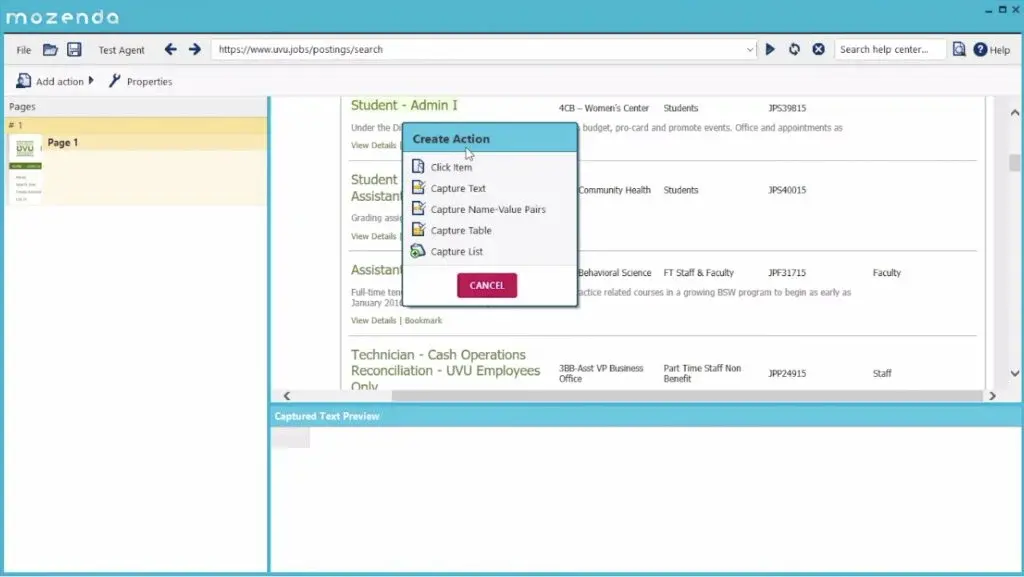
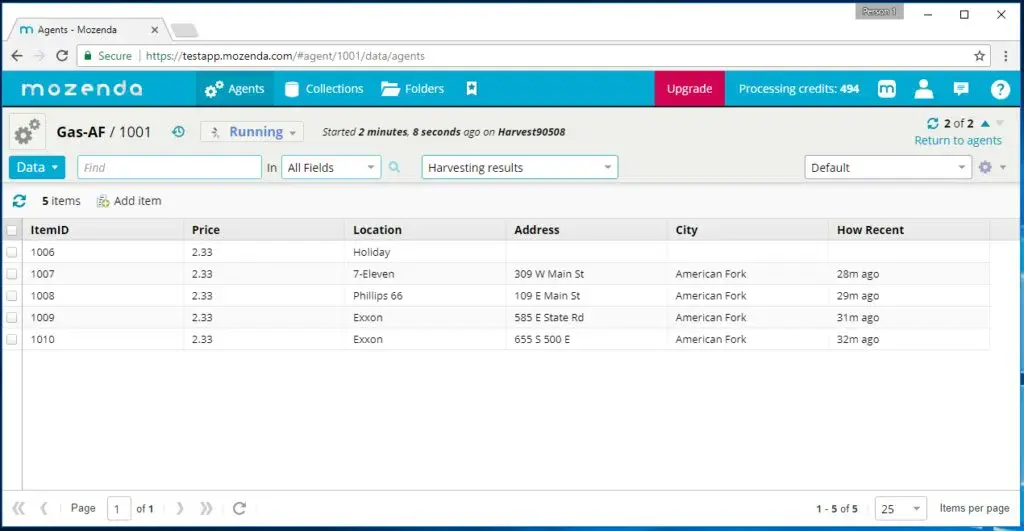
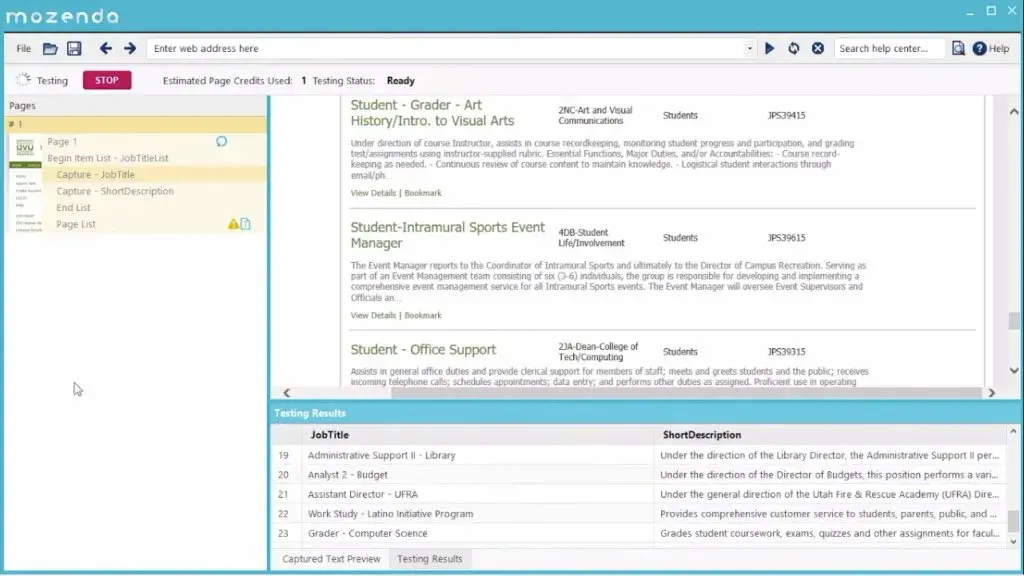
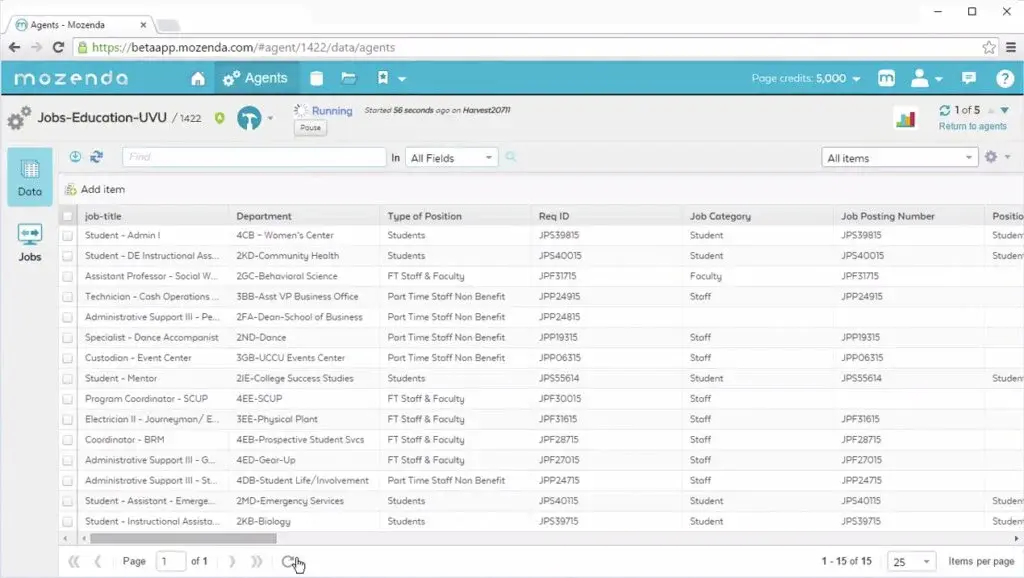
Mozenda Alternatives
#1 ParseHub

ParseHub is an online platform that offers a dynamic web scraping tool to extract data with few clicks. It enables you to scrape data quickly from any website, page, or any other place without any hassle. You can easily access data with the help of JSON, API, and Excel. It requires no coding to extract data from any website, you have to just click on the data, and all the data will be extracted instantly. This platform provides a machine learning relationship engine that automatically monitors pages and understands all the hierarchy of elements.
ParseHub allows you to enter hundreds of keywords or links to get data from all web pages smoothly. It will enable you to download all the extracted data in JSON and excel. You can also import all your results in Tableau and Google Sheets. There is also a schedule option to get data sets daily, weekly, or monthly as per your choice. It removes HTML and text before downloading data and offers API to integrate data anywhere. Moreover, ParseHub is a cloud-based platform that automatically stores and collects all your data on servers.
#2 Beautiful Soup
Beautiful Soup is an advanced Python library that comes with the exclusive service of data pulling from XML and HTML files. It helps you to get all the required data from any webpage without any effort. You can easily save data from any page or website and use it in your research. It works with multiple parsers that help programmers navigate, modify, and search data within a minimum time. This modern platform automatically converts outgoing documents to UTF-8 and incoming documents to Unicode.
Beautiful Soup quickly parses anything you command to it, such as “Find all the links” or “Find the table heading that’s got bold text, then give me that text.” You can even extract all the locked-up valuable data in any poorly designed websites. Moreover, it uses popular Python parsers like html5lib and lxml to try different parsing trade speeds or strategies for more flexibility.
#3 WebScraper.io

WebScraper.io is an innovative tool that can easily extract data from any website or page. It is an intuitive and easy-to-use tool through which you can extract all your desired data in a single click. You can enjoy the fastest speed of data extraction in the most convenient way. It can smoothly extract thousands of records from multiple poorly designed websites. This advanced tool structure has many selectors that instruct the scraper about the data extraction and site targeting.
WebScraper.io integrates with multiple websites and can even mine data from dynamic websites, including Tripadvisor, eBay, Amazon, and many more. It requires no JavaScript, Python, or PHP coding for scraping data of multiple types, including images, text, URLs, etc. You can also download data as a CSV file or export it into Excel or Google Sheets without any difficulty. This tool also offers cloud-based services that can automatically store and extracts data.
#4 WebHarvy

WebHarvy is a leading platform that automatically identifies data patterns occurring in web pages. It instantly starts scraping data from multiple websites within a few minutes. You can extract data from all websites such as form submission, handles login, and so forth. It requires no scripts or code and allows you to extract the desired data in a couple of clicks. You are entitled to save the extracted data in multiple files, including XML, JSON, TSV, Excel, or CSV. This platform also offers you target websites via VPN or proxy servers to prevent blocking of scraping software by web servers.
WebHarvy can automatically browse multiple tasks like Scrolling page, Clicking links, Opening Popups, and many more. It seamlessly extracts image URLs and downloads images from many e-commerce websites. This platform offers many features such as category scraping, regular expressions, JavaScript support, technical assistance, intelligent pattern detection, and many more.
#5 WebSundew

WebSundew is a popular platform that comes with the exclusive service of web data extraction in a perfect way. You can instantly extract data from any website with one click and without any need for codes or software developers. It provides accurate data by which you can smoothly analyze, collect and get profit from data. You are allowed to capture data from any website, including JavaScript, OnePage, Ajax, and many more. This modern platform offers multiple types scrapping such as files, image, etc. it exclusively format, convert, analyze and clean data as per your desire and commands.
WebSundew smoothly works on multiple operating systems like Mac, Linux, or Windows. It allows you to use both versions of Cloud or Desktop for effective extraction of data. All the extracted data can be used for many businesses, including retail, automotive, e-commerce, and many more.
#6 Web Robots

Web Robots is a best-in-class platform that provides exclusive services of scraping from numerous websites. It automatically locates and detects data from any web page like OnePage, JavaScript, Ajax, and so forth. You can get all the valuable extracted data in CSV or Excel files that can help you to make better and big business decisions. It can smoothly run in your Edge or Chrome browser as an extension without any difficulty. Moreover, this platform allows you to see source code, reports, statistics, and data on the customer portal.
Web Robots require no code or scripts and quickly extract data from websites. It provides advanced and deep web crawling that can smoothly scrape data even from poorly designed websites. Moreover, it saves data in cloud storage and inserts into customers’ database.
#7 ScrapeHero

ScrapeHero is a unique platform that offers the best services of data scraping from multiple websites. It seamlessly extracts data from different websites and checks data quality by Artificial Intelligence. You will get automated alerts in case of any change in quality, website structure, and quality. It offers you data in any format such as in CSV, XML, Excel, JSON that fulfills your requirements. For your more facilitation and engagement, it integrates with various cloud storages, including DropBox, Google Cloud Storage, FTP, Microsoft Azure, and Amazon S3.
ScrapeHero provides always-available technology and business processes experts that are always ready to help. It offers data extraction for many fields such as research, journalism, social media, sales, travel, real estate, housing, stock market, financial, and many more. This platform provides the fastest data extraction service that you can utilize for better business decisions.
#8 Zyte

Zyte (formerly known as Scrapinghub) is a great platform that provides web scraping services to extract meaningful data for your business and other requirements. It provides an automated facility that extracts high-quality and valuable data from multiple websites. You can utilize all the extracted data for better and unique business decisions. It offers you data in different files or formats such as Excel, JSON, CSV, XML, and many more. This platform works according to your instructions and tries to fulfill all your data requirements or needs.
Zyte requires no coding and demands URLs to provide quality data in the minimum time. It has an advanced built-in system that evaluates risks or issues and advises data teams for the best services. You are freely allowed to ask multiple questions to support questions, and in return, get the best solutions. Moreover, this platform provides clean, relevant, and usable wen data to drive business insights.
#9 Helium Scraper

Helium Scraper is an online platform that offers the fastest extraction of all your required data. It provides an intuitive and clicks interface that allows you to add actions from a predefined list. You are allowed to define your actions or quickly use custom JavaScript for more complex and extensive scenarios. It offers you to export data to any format such as Excel, JSON, XML, SQLite, or CSV. This platform has a modern built-in system that automatically detects table rows and lists on websites.
Helium Scraper offers you efficiently enter a list of proxies and rotate them at any given interval according to your desire. It can accurately detect similar elements from one or two samples. You will get the fastest extraction because it immediately blocks unwanted web requests and images. More hot features are API calls, scheduling, JavaScript support, text manipulation, SQL generation, big data, and so forth.
#10 Apify

Apify is a reliable platform for automation workflow that allows you to Crawl lists of URLs, extract data from websites. You can turn any website into an API in a matter of no time, and you have everything necessary for the robotic process automation. Apify crawls and extract structured data from the arbitrary websites and export them into multiple files like CSV, JSON, or excel and benefits organizations with full potential web to forward their thinking.
Apify brought multiple web integration for you to connect different web services and APIs. Just let the data flow between them, and you can add data processing and custom computing steps as well. You can generate all-important insights with the data available on the web publicly, and simple lead generation means you can find new customers. Apify advantages you with the machine learning process to generate large scale datasets to train your artificial intelligence model. Moreover, the software is dispensing online competitors, product development, cloud computing, universal HTTP proxies, specialized data storage, and SDK service.
#11 Web Content Extractor

Web Content Extractor is an estimable and easy to use web scraping software that allows you to extract specific data, images, and files from any website. The software saves your hours for extracting files courtesy of automated software that does the tricks for you in a matter of no time. Web Content Extraction is designed on the robust functionality to increase the work rate that, in turn, enhance productivity and effectiveness of the web data scraping process.
The software is available in a desktop version, but the cloud version allows you to configure and run the scraping task in the cloud. The multiple features offered by Web Content Extractor include ultimate extraction for all the typical tasks, powerful web crawl engine for nimble data extractions, automation to web scraping task, reliable and intuitive design, and more. Web Content Extractor can be accessible from any web browser on any operating system, and you need to install anything on your system, and all you need a good internet connection.
#12 Screen Scraper

Screen Scraper is a web data extraction tool that allows users to extract data from any website according to their requirement and save it online or download it. The platform comes with the much-needed experience as it is one of the oldest platforms performing the data extraction work in the market.
It allows users to download text, images, and other content automatically, and users can extract anything with lightning speed. It delivers data in the format users can use, such as TXT, HTML, CSV, etc. Moreover, users have to tell the site and the kind of data they want to extract to the software.
Screen Scraper manages everything, and users do not have to do anything and let the data flowing. Different industries can benefit through software such as the medical sector can gather health plans from different sites with a click. Lastly, it comes with free and paid versions.
#13 FMiner

FMiner is a tool that comes with powerful and user-friendly web scraping and data extracting features. The software comes with a visual design tool that makes the data mining project a breeze. The platform requires no coding, and users can start using it right after installing it. Moreover, it allows users to drill through the site pages through the combination of link structures.
The software offers multi-level nested extractions that help users in linking structures to capture directory content and product catalog. Moreover, it comes with a multi-browser crawling capability, which increases the pace of data extraction.
FMiner enables users to export data in different formats such as Excel, CSV, HTML, and can also export data to popular databases such as MS SQL, or Oracle. Lastly, it allows users to scrape dynamic pages in the context of static pages, and users can receive an email report when the process completes.
#14 Diffbot

Diffbot is a platform that allows users to transform their web into data and helps in extracting data and saving it in different formats. The platform uses machine learning that allows users to transform the internet into accessible and structured data.
It allows users to get any kind of data from the web without any trouble and expenses. The platform analyzes the web pages like a human and extracts the relevant data that users require. Users can use its API, which crawls all over the platform and find products that users asked, such as articles or videos.
Diffbot comes with a crawling bot that extracts data from entire sites irrespective of the fact what users want. However, users can use its structured feature to find articles on sites according to the required context. Lastly, it provides a relationship graph to users to let them understand how web items are related.